2019年“网红”芯片大盘点,哪一颗让你印象最深刻?
本年的芯片发布会是一场接着一场,不论是传统芯片厂商,亦或者一些新进者,都在2019年牟足了劲,秀一把芯片实力。今天,我们就来看一看,都有哪些芯片“冷艳”了2019年。
文︱Aaron
图︱收集
关于半导体圈来说,2019年绝对是一个不服凡的一年。就拿最新的数据来说,世界半导体商业统计协会(WSTS)称,2019年全球半导体市场规模自上次(6月)预估的4120.86亿美圆(年减12.1%)下修至4089.88亿美圆、估计年减12.8%,将创自IT泡沫幻灭后的2001年(年减32.0%)以来的更大减幅。
即使如斯,本年的芯片发布会也是一场接着一场,不论是传统芯片厂商,亦或者一些新进者,都在2019年牟足了劲,秀一把芯片实力。今天,我们就来看一看,都有哪些芯片“冷艳”了2019年。
华为末端5G芯片巴龙5000和5G基站芯片天罡
1月24日,华为发布了两款5G芯片,别离是5G 基站核心芯片华为天罡和5G末端的基带芯片巴龙5000。
此中,天罡初次在极低的天面尺寸规格下, 撑持大规模集成有源PA(功放)和无源阵子;极强算力,实现2.5倍运算才能的提拔,搭载最新的算法及Beamforming(波束赋形),单芯片可控造高达业界更高64路通道;极宽频谱,撑持200M运营商频谱带宽。此外,天罡也为AAU 带来了革命性的提拔,实现基站尺寸缩小超50%,重量减轻23%,功耗节省达21%,安拆时间比尺度的4G基站,节省一半时间。
材料显示,巴龙5000具备5项世界之最,1个世界领先:全球领先的集成2G、3G、4G的多模单行模组;速度世界最快,Sub-6 GHz 200MHz:下行链路速度4.6Gbps,上行速度2.5Gbps。世界首个上行/下行解耦多模末端芯片;世界首个同时撑持NSA和SA架构的芯片组;世界最快的顶峰下行速度:毫米波 800MHz Gbps;世界首个5G芯片上的R14 V2X。
依图科技“求索”
5月9日,依图科技发布一款云端深度进修推理定造化SoC芯片——依图芯片questcore,中文名“求索”。
材料显示,那款深度进修云端定造SoC芯片从设想到造造实现全面国产化,拥有自主常识产权的ManyCore架构,基于范畴公用架构(Domain Specific Architecture,DSA)理念,专为计算机视觉应用而生,针对视觉范畴的差别运算停止加速,适用于人脸识别、车辆检测、视频构造化阐发、行人再识别等多种视觉推理使命。
据介绍,在现实的云端应用场景,依图questcore更高能供给每秒15 TOPS的视觉推理性能,更大功耗仅20W,比一个通俗的电灯胆还小。
在同等功耗下,questcore的视觉推理性能是市道现有支流同类产物的2~5倍,其安防摄像头单路功耗仅为英伟达GPU P4的30%。
华为麒麟810
6月21日,华为在湖北武汉的发布会上推出了新款手机芯片麒麟810,总体来看,核心亮点包罗:台积电7nm造程工艺,华为自研达芬奇架构NPU,旗舰版A76大核CPU,定造GPU,旗舰版IVP和ISP。
百度远场语音交互芯片“鸿鹄”
7月3日,在2019百度AI开发者大会上,百度发布一款新的芯片远场语音交互芯片“鸿鹄”。
鸿鹄芯片利用了HiFi4自定义指令集,双核DSP核心,均匀功耗仅100mW。那款芯片是按照车规级尺度打造,将为车载语音交互、智能家具等场景带来庞大的便当。
阿里RISC-V处置器玄铁910
7月25日,在上海举办的 2019 阿里云峰会上,阿里巴巴集团副总裁戚肖宁博士颁布发表推出业界最强的 RISC-V 处置器——玄铁 910。
玄铁 910 接纳 16core 构造,12 级乱序流水线,并行 3 发射 8 施行 2 内存拜候,更大撑持 8MB 二级缓存,AI 加强的向量计算引擎。
在性能上,玄铁 910 较支流的 RISC-V 指令性能提拔 40%,较尺度指令提拔 20%。戚肖宁介绍,那源于平头哥系统架构、指令系统、系统优化,以及中天微十余年的量产经历而到达的整体效果。
阿里方面介绍,玄铁910撑持16核,单核性能到达7.1 Coremark/MHz,主频到达2.5GHz,比目前业界更好的RISC-V处置器性能高40%以上。
并且玄铁面向AIoT,面向更丰硕的万物互联场景,性能更高,适用性更广,开发和进一步流片量产的门槛更低。
清华天机类脑芯片架构登上Nature封面
8月1日,顶级学术期刊《Nature》的封面文章登载了清华大学施路平团队近日发布的研究功效——类脑计算芯片“天机芯”。该功效实现了中国在芯片和人工智能两大范畴《Nature》论文零的打破。
28nm的天机芯片由156个FCores构成,面积为3.8×3.8毫米,包罗大约40000个神经元和1000万个突触,能够同时撑持机器进修算法和类脑电路。那篇论文名为《面向通用人工智能的异构交融芯片架构“天机”(Towards artificial general intelligence with hybrid Tianjic chip architecture)》。
世界更大芯片
8月19日,Cerebras公司发布了全球更大的芯片WSE(Wafer Scale Engine),专注于AI运算,总计1.2万亿个晶体管,核心面积超越46225mm2,集成了40万个核心以及18GB SRAM缓存,带宽超越100Pb/s。WSE芯片基于台积电16nm工艺。
WSE将逻辑运算、通信和存储器集成到单个硅片上,是一种专门用于深度进修的芯片。它创下了4项世界纪录:
晶体管数量最多的运算芯片:总共包罗1.2万亿个晶体管。固然三星曾造出2万亿个晶体管的芯片,却是用于存储的eUFS。
芯全面积更大:尺寸约20厘米×23厘米,总面积46,225平方毫米。面积和一块晶圆差不多。
片上缓存更大:包罗18GB的片上SRAM存储器。
运算核心最多:包罗40万个处置核心。
赛灵思更大容量FPGA
Virtex UltraScale+VU19P
8月22日赛灵思公司(Xilinx)在其于美国硅谷举办的赛灵思首届立异日(Innovation Day)前夕正式推出目宿世界上更大容量的FPGA – Virtex UltraScale+ VU19P。
据悉,那款VU19P接纳16nm工艺,基于Arm架构,拥有350 亿个晶体管,即有史以来单颗芯片更高逻辑密度和更大I/O 数量,能够撑持将来更先进ASIC 和SoC 手艺的仿实与原型设想。同时,VU19P也将普遍撑持测试丈量、计算、收集、航空航天和国防等相关应用。
材料显示,VU19P拥有900 万个系统逻辑单位、每秒高达1.5 Terabit 的DDR4 存储器带宽、每秒高达4.5 Terabit 的收发器带宽和超越2,000 个用户I/O。它为创建当今最复杂SoC 的原型与仿实供给了可能,同时它也能够撑持各类复杂的新兴算法,如用于人工智能(AI)、机器进修(ML)、视频处置和传感器交融等范畴的算法。比拟上一代业界更大容量的FPGA ( 20 nm 的UltraScale 440 FPGA ) ,VU19P 将容量扩大了1.6 倍。
地平线国内首款已量产车规级边沿AI视觉芯片——征程2.0
8月30日,地平线推出国内首款车规级 AI 芯片——地平线征程二代 Jounrney 2,面向 ADAS 市场感知计划,那是一款已经步入贸易化阶段的成熟芯片。
征程二代接纳双核 Cortex A53 处置器,双核地平线第二代 BPU(伯努利架构),满足车规级 AEC-Q100,等效算力超越 4Tops,典型功耗 2 瓦,接纳台积电 28nm 造程工艺,17*17mm BGA 封拆工艺。
在性能亮点方面,征程二代可将典型算法模子的算力操纵率提拔到 90% 以上,每 TOPS 算力可处置的帧数同等算力 GPU10 倍以上。感知才能方面,可实现像素级语义朋分,每帧高达 60 个目的及其特征的准确感知与输出,车辆及行人测距测速误差均优于国际同等支流计划,识别精度超越 99%,每秒识别目的数超越 2000 个。
华为麒麟990
2019年9月6日,华为在德国柏林和北京同时发布麒麟990和麒麟990 5G两款手机芯片。
发布会上华为暗示,麒麟990处置器是业界首款旗舰5G SoC(System on Chip 系统级芯片)芯片,拥有更佳5G、更佳AI与更佳性能体验,利用的是台积电二代的7纳米工艺造造,集成巴龙5000 5G基带芯片,同时撑持 SA/NSA两种5G组网形式,由4个A76大核+4个A55小核构成,还有十六核GPU,整体性能会比麒麟980提拔10%摆布。
比特大陆第三代云端AI推理芯片BM1684
9月17日,比特大陆正式发布其第三代AI芯片BM1684,该芯片接纳台积电12nm工艺造程,Winograd卷积加速下INT8算力可达35.2TOPS,典型功耗仅16W,为视频构造化和加解密算法均做了出格优化。据称是全球独一一个城市大脑公用芯片。
此外,比特大陆结合开创人兼董事长詹克团暗示,7nm云端AI芯片BM1686将于明年发布。
阿里平头哥AI芯片含光800
在9月25日的杭州云栖大会上,达摩院院长张建锋现场展现了那款全球最强的AI芯片——含光800。在业界尺度的ResNet-50测试中,含光800推理性能到达78563 IPS,比目前业界更好的AI芯片性能高4倍;能效比500 IPS/W,是第二名的3.3倍。在杭州城市大脑的营业测试中,1颗含光800的算力相当于10颗GPU。
清华大学湃方科技AI芯片Tritium 103
10月22日,清华大学湃方科技发布人工智能(AI)芯片产物阵列,包罗Sticker系列AI芯片IP核、面向视觉应用的首款超低功耗嵌入式AI协处置器Tritium 103、工业视觉边沿计算平台Reactor。
图源见水印
Sticker系列AI芯片能效更高达140.3 TOPS/W,功耗低于40mW,曾在本年7月底的ISLPED 2019上获得设想竞赛一等奖,已在中石油、中石化、山东双轮等行业龙头企业停止了应用,可满足聪慧工业、聪慧城市、智能造造等各类高能效、高性能应用场景的需求。
科大讯飞AI芯片CSK400X系列
10月24日,科大讯飞推出了科大讯飞云端语音操做系统2.0和人工智能物联网平台,并拿出了讯飞与穹天科技结合打造的家电财产公用语音AI芯片CSK400X系列,以及基于CSK400X的四套智能家电模组。
据介绍,此次发布的语音AI芯片CSK400X系列,算力可达128GOPS/s,集成了讯飞的语音AI算法,能够通过深度神经收集算法处理家居中的噪音问题,同时还撑持200个唤醒词做为号令词。
地平线旭日二代边沿AI芯片
10月29日,地平线正式发布了旭日二代边沿AI芯片及一站式全场景芯片处理计划。
旭日二代是地平线面向将来物联网推出的新一代智能应用加速引擎,也是地平线在主动驾驶芯片范畴手艺先发优势的一次胜利迁徙。旭日二代上的现实测试成果表白,分类模子MobileNetV2的运行速度超越每秒700张图片,检测模子YoloV3的运行速度超越每秒40张图片。
在运行那些业界领先的高效模子方面,旭日二代可以到达以至超越业内标称4TOPS算力的AI芯片,而其功耗仅为2W。
英特尔Movidius VPU和Nervana NNP
11月13日凌晨,Intel在旧金山举办的人工智能峰会上正式发布了新一代英特尔Movidius VPU(视觉处置单位),代号为Keem Bay,可用于边沿媒体、计算机视觉和推理应用,并方案于明年上半年上市。
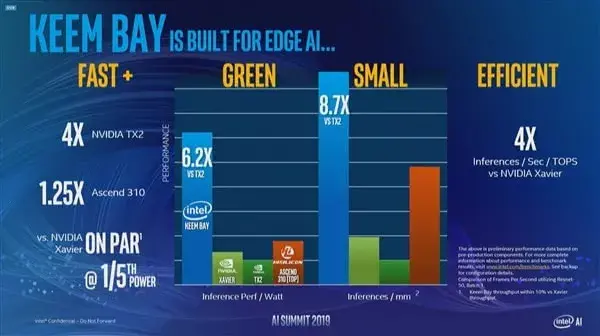
据介绍,Keem Bay的性能相较上一代VPU提拔了10倍以上,到达了英伟达的TX2的4倍,华为Ascend 310的1.25倍,而且功耗也只要约30W。Intel暗示,若是能充实操纵Intel OpenVINO东西包的开发者能够再获得50%的额外性能。别的,在特定情况下,Keem Bay每瓦性能比英伟达TX2超出跨越了6.2倍。在单元面积所能供给的推理性能密度上,Keem Bay到达了英伟达TX2的8.7倍。
Intel暗示,Keem Bay将于2020年上半年推出,落地形式包罗PCIe接口和M.2接口的产物。
此外,英特尔展现了面向训练(NNP-T1000)和面向推理(NNP-I1000)的Nervana 神经收集处置器(NNP)。
据官方介绍,NNP-I是全新构建的,具备高能效和低成本,且其外形规格灵敏,十分合适在现实规模下运行高强度的多形式推理。NNP-T针对深度进修训练开发,在计算、通信和内存之间获得了平衡,最末的目标是赋能散布式训练。
点击查看《英特尔2019年发布的所有芯片》
联发科天玑1000
11月26日,联发科发布了旗下首款集成5G调造解调的智妙手机SoC挪动平台——天玑1000。

据材料显示,天玑1000接纳7nm工艺造造,CPU部门集成4个ARM Cortex-A77核心和4个ARM Cortex-A55核心,此中大核主频高达2.6GHz,小核主频为2.0GHz。图形处置器方面,天玑1000接纳ARM Mali-G77 GPU芯片。据悉Mali-G77可在5G速度下带来酣畅的流媒体和游戏体验。同时,天玑1000撑持120Hz的FHD+显示和90Hz的2K+显示,而且它是全球第一个撑持4K分辩率下60帧谷歌AV1格局的挪动平台。
此外,天玑1000集成MediaTek 5G调造解调器,除了节省能耗外,还撑持5G双载波聚合(2CC CA)手艺,同时也是全球第一款撑持5G双卡双待的芯片。论速度,天玑1000 在Sub-6GHz频段到达4.7Gbps下行和2.5Gbps上行速度。它还撑持Sub-6GHz频段SA独立组网与NSA非独组网,以及2G到5G的各代蜂窝收集毗连。
Imagination的IMG A系列
12月3日,Imagination Technologies公司针对图像及视频应用,发布了PowerVR 第十代(Series10)图形处置架构IMG A系列(IMG A-Series)。据称,IMG A系列是Imagination Technologies有史以来发布的性能最强大的图形处置器(GPU)半导体常识产权(IP)产物,初次搭载该IP的SoC器件估计在2020年出货。

IMG A系列在不异的时钟和半导体工艺上,比正在出货的PowerVR设备性能进步了2.5倍,机器进修处置速度进步了8倍,且功耗降低了60%。据称,与当前可用的其它GPU IP比拟,IMG A在性能、功耗、带宽和面积上都有优化,而且具有包罗确保50%的图像压缩数据等特异性优势。
高通骁龙865和小龙765/765G
北京时间12月4日,在高通骁龙手艺峰会首日,高通正式发布了最新处置器小龙865 和小龙765/765G。

小龙865仍然没有集成基带。高通暗示,小龙865搭载了X55 5G基带,接纳了第5代AI引擎,撑持了HDR10+,5G收集方面则是撑持mmWave毫米波,Sub-6 GHz, CA, DSS, 独立和非独立组网。高通骁龙865的AI性能到达了15 TOPS,是上代的两倍,撑持 8K30 帧或者是64MP 4K视频拍摄,更高撑持200 MP的相机。
性能方面,高通骁龙865的GPU性能提拔了25%,将给手机游戏带来桌面版的体验。综合性能方面,高通暗示小龙865 在 CPU、GPU 等项目中持续性能第一。
小龙865平台包罗SoC处置器、小龙X55基带和相关组件两大部门,此中SoC处置器接纳台积电7nm工艺造造(小龙765/小龙765G是三星7nm EUV),内部集成Kryo 485 CPU处置器、Adreno 650 GPU图形核心、Spectra 480 CV-ISP计算视觉图像处置器、Hexagon 698 DSP信号处置器、传感器中枢(Sensing Hub)、SPU平安处置器、内存控造器等诸多模块。
以上所发布的芯片,哪一款让你印象最深入呢?若有遗漏,欢送在评论区弥补。
(微信公家号搜刮“TechSugar”并存眷,让我们做你身边最值得相信的科技媒体!)
版权声明
本文仅代表作者观点,不代表木答案立场。