什么是Rasch模型?
泻药,
几个月以来,我不断对序数回归与项目响应理论(IRT)之间的关系感兴趣。 在那篇文章中,我重点介绍Rasch阐发。
比来,我花了点时间测验考试理解差别的预算办法。三种最常见的预算办法是:
结合更大似然(JML)前提逻辑回归,在文献中称为前提更大似然(CML)。尺度多级模子,在丈量文献中称为边际更大似然(MML)。原文链接:
拓端数据科技 / Welcome to tecdattecdat.cn/?p=10175阅读后,我决定测验考试停止Rasch阐发,产生多个Rasch输出。
规范停止此演示之后,可能需要ggplot2和dplyr的常识才气创建图表。
library(Epi) # 用于带比照的前提逻辑回归
library(lme4) # glmer
library(ggplot2) # 用于绘图
library(dplyr) # 用于数据操做数据。
raschdat1 <- as.data.frame(raschdat1) CML预算 res.rasch <- RM(raschdat1)系数
coef(res.rasch)
beta V1 beta V2 beta V3 beta V4 beta V5
1.565269700 0.051171719 0.782190094 -0.650231958 -1.300578876
beta V6 beta V7 beta V8 beta V9 beta V10
0.099296282 0.681696827 0.731734160 0.533662275 -1.107727126
beta V11 beta V12 beta V13 beta V14 beta V15
-0.650231959 0.387903893 -1.511191830 -2.116116897 0.339649394
beta V16 beta V17 beta V18 beta V19 beta V20
-0.597111141 0.339649397 -0.093927362 -0.758721132 0.681696827
beta V21 beta V22 beta V23 beta V24 beta V25
0.936549373 0.989173502 0.681696830 0.002949605 -0.814227487
beta V26 beta V27 beta V28 beta V29 beta V30
1.207133468 -0.093927362 -0.290443234 -0.758721133 0.731734150利用回归raschdat1.long$tot <- rowSums(raschdat1.long) # 创建总分
c(min(raschdat1.long$tot), max(raschdat1.long$tot)) #最小和更大分数
[1] 1 26
raschdat1.long$ID <- 1:nrow(raschdat1.long) #创建ID
raschdat1.long <- tidyr::gather(raschdat1.long, item, value, V1:V30) # 宽数据转换为长数据
# 转换因子类型
raschdat1.long$item <- factor(
raschdat1.long$item, levels = p前提更大似然# 回归系数
item1 item2 item3 item4 item5
0.051193209 0.782190560 -0.650241362 -1.300616876 0.099314453
item6 item7 item8 item9 item10
0.681691285 0.731731557 0.533651426 -1.107743224 -0.650241362
item11 item12 item13 item14 item15
0.387896763 -1.511178125 -2.116137610 0.339645555 -0.597120333
item16 item17 item18 item19 item20
0.339645555 -0.093902568 -0.758728000 0.681691285 0.936556599
item21 item22 item23 item24 item25
0.989181510 0.681691285 0.002973418 -0.814232531 1.207139323
item26 item27 item28 item29
-0.093902568 -0.290430680 -0.758728000 0.731731557请留意,item1是V2而不是V1,item29是V30。要获得第一个项目V1的难易水平,只需将项目1到项目29的系数乞降,然后乘以-1。
显然,所有数据(30 * 100)都用于预算。那是因为没有一个参与者在所有问题上都得分为零,在所有问题上都得分为1(更低为1,更高为30分中的26分)。所有数据都有助于估量,因而本示例中的方差估量是有效的
结合极大似然估量# 尺度逻辑回归,请留意利用比照
res.jml
# 前三十个系数
(Intercept) item1 item2 item3 item4
-3.688301292 0.052618523 0.811203577 -0.674538589 -1.348580496
item5 item6 item7 item8 item9
0.102524596 0.706839644 0.758800752 0.553154545 -1.148683041
item10 item11 item12 item13 item14
-0.674538589 0.401891360 -1.566821260 -2.193640539 0.351826379
item15 item16 item17 item18 item19
-0.619482689 0.351826379 -0.097839229 -0.786973625 0.706839644
item20 item21 item22 item23 item24
0.971562267 1.026247034 0.706839644 0.002613624 -0.844497142
item25 item26 item27 item28 item29
1.252837340 -0.097839229 -0.301589647 -0.786973625 0.758800752item29与V30不异。差别是由预算办法的差别引起的。要获得第一个项目V1的难易水平,只需将项目1到项目29的系数乞降,然后乘以-1。
sum(coef(res.j
[1] 1.625572多级逻辑回归或MML我希望回归系数是项目抵达时的难易水平,而且glmmTMB()不供给比照选项。我要做的是运行glmer()两次,将第一次运行的固定效果和随机效果做为第二次运行的起始值。
利用多级模子复造Rasch成果供给人员-物项目映射:
plotPImap(res.rasch)要创建此图,我们需要项目难度(回归系数* -1)和人员才能(随机截距)。
极端的分数是差别的。那归因于MML的差别。因为CML不供给报酬因素,因而必需利用两步排序过程。
项目特征曲线eRm用一条线供给项目特征曲线:
plotjointICC(res.rasch)在那里,我们需要可以按照学生的潜能来预测学生准确答题的概率。我所做的是利用逻辑方程式预测概率。获得该数值,就很容易计算预测概率。因为我利用轮回来施行此操做,因而我还要计算项目信息,该信息是预测概率乘以1-预测概率。
## GGPLOT可视化
ggplot(test.info.df, aes(x = theta, y = prob, colour = reorder(item, diff, mean))) +
geom_line() +ct response", colour = "Item",下面将逐项绘造
ggplot(test.info.df, aes(x = theta, y = prob)) + geom_line() +
scale_x_continuous(breaks = seq(-6, 6, 2), limits = c(-4, 4)) +
scale_y_continuous(labels = percent, breaks = seq(0, 1, .人员参数图
plot(person.parameter(res.rasch))我们需要估量的人员才能:
ggplot(raschdat1.long, aes(x = tot, y = ability)) +
geom_point(shape = 1, size = 2) + geom_line() +
scale_x_continuous(breaks = 1:26) +
theme_classic()项目均方拟合关于infit MSQ,施行不异的计算。
eRm:
ggplot(item.fit.df, aes(x = mml, y = cml)) +
scale_x_continuous(breaks = seq(0, 2, .1)) +
scale_y_continuous(breaks = seq(0, 2, .1))似乎CML的MSQ几乎老是比多级模子(MML)的MSQ高。
eRm:
来自CML的MSQ几乎老是比来自多条理模子(MML)的MSQ高。我利用传统的临界值来识别不合适的人。
测试信息eRm:
plotINFO(res.rasch)创建ICC计算测试信息时,我们已经完成了上述工做。关于总体测试信息,我们需要对每个项目标测试信息停止汇总:
最初,我认为利用尺度丈量误差(SEM),您能够创建一个置信度带状图。SEM是测试信息的反函数。
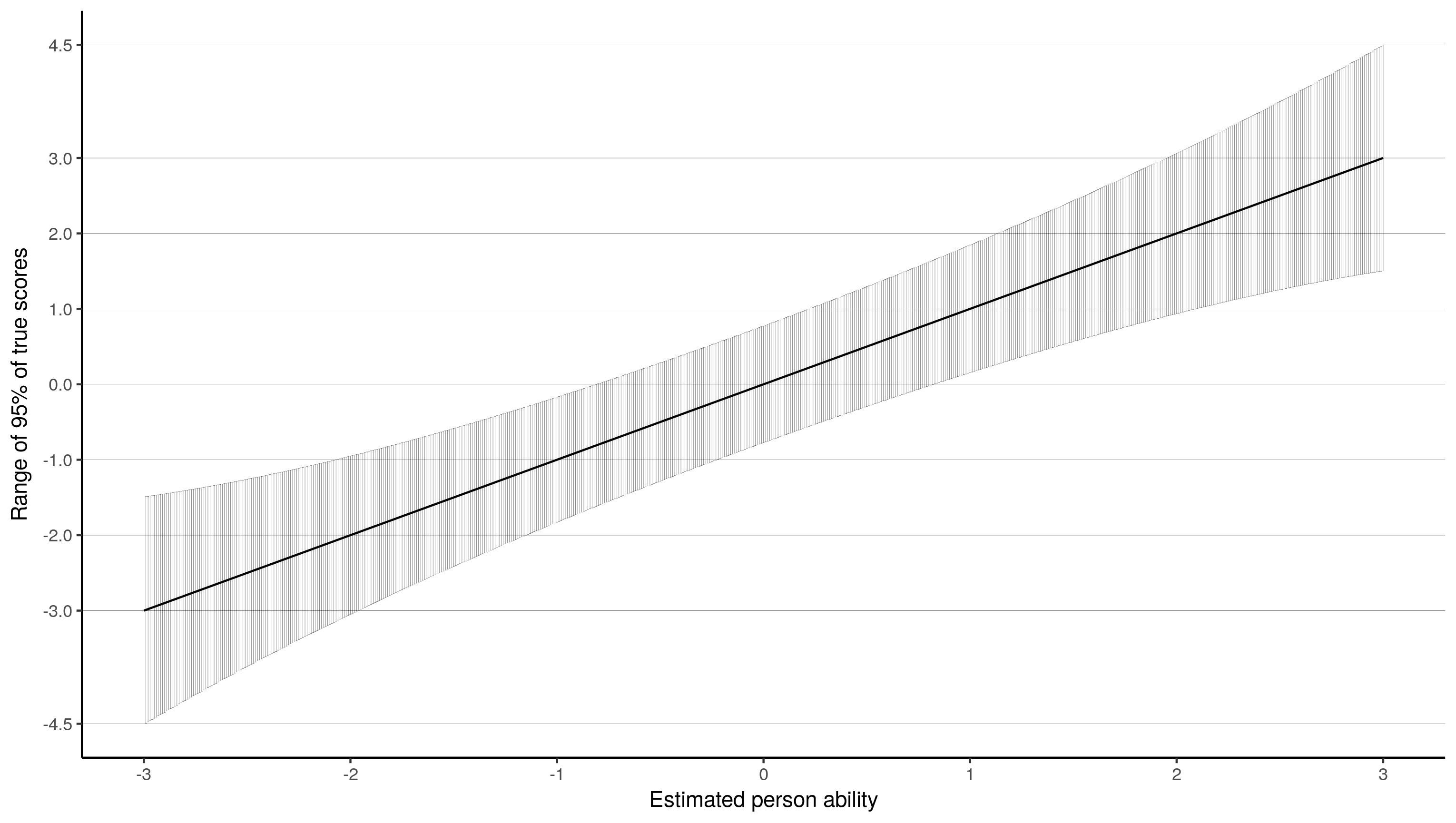
该图表白,关于一个估量的才能为-3的孩子,他们的才能的估量精度很高,他们的现实分数可能在-1.5和-4.5之间。
颠末那一工做,我觉得我能够更好天文解该模子,以及此中的一些内容诊断。

更受欢迎的见解
1.R语言Wald查验 vs 似然比查验
2.R语言多元Logistic逻辑回归 应用案例
3.matlab中的偏最小二乘回归(PLSR)和主成分回归(PCR)
4.R语言泊松Poisson回归模子阐发案例
5.R语言LME4混合效应模子研究教师的受欢送水平
6.r语言中对LASSO回归,Ridge岭回归和Elastic Net模子实现
7.R语言用Rshiny摸索lme4广义线性混合模子(GLMM)和线性混合模子(LMM)
8.基于R语言的lmer混合线性回归模子
9.R语言里的非线性模子:多项式回归、部分样条、光滑样条、广义加性模子阐发
版权声明
本文仅代表作者观点,不代表木答案立场。